在这个信息爆炸的时代,我们每天都在产生大量的语音数据:冗长的学术访谈、头脑风暴式的部门会议、长达数小时的行业讲座。过去,面对这些动辄两三个小时的录音,我们只能依靠键盘和耳机,频繁地按下暂停和倒退键,将大把的精力消耗在机械的文字转录上。而如今,随着人工智能技术的狂飙突进,智能AI声音处理已经从简单的“语音转文字”工具股票配资十大平台,进化成了能够深度理解上下文的“知识提取引擎”。
很多人或许会好奇,现在的AI究竟是如何“听懂”复杂人声,甚至比人类记录员还要敏锐的?
从技术原理上来看,现代智能声音处理早已跳出了早期单纯依赖声学模型(Acoustic Model)的框架。当一段音频被输入系统后,AI首先会通过前端处理技术进行降噪和人声增强,过滤掉背景里的白噪音或电流声。紧接着,底层的大型自然语言处理(NLP)模型开始介入。它不仅仅是在做音节到汉字的映射,更是在进行“语义预测”。这就解释了为什么当录音中出现发音模糊的专业术语时,现代AI能够根据上下文的语境,自动纠正并匹配出正确的词汇,而不是像老式软件那样给出令人啼笑皆非的同音字错误。
更令人惊叹的是“声纹识别”与“说话人分离(Speaker Diarization)”技术。在多人交谈的场景中,AI会提取每个人声音中独特的声学特征(比如基频、共振峰等),就像识别指纹一样,将交织在一起的音频流精准地切割、分类。它能清楚地知道何时是“发言人A”在陈述,何时是“发言人B”在反驳,从而构建出逻辑清晰的对话结构。
谈到这里,我想分享一段上周我们部门会议的真实体验,这或许能更直观地展现现代智能AI声音处理的魅力。
那是一场长达三个小时的Q3季度业务规划会。会议室里坐了八位来自不同业务线的同事,讨论氛围非常热烈。不仅有高频的观点交锋,还夹杂着大量诸如“用户留存率”、“转化漏斗”、“DAU增长模型”等互联网黑话,有时甚至会出现两三个人抢话的交叉发言阶段。按照以往的经验,作为会议记录者,我通常需要在会后花费至少大半天的时间去反复听录音,才能梳理出勉强可用的纪要。
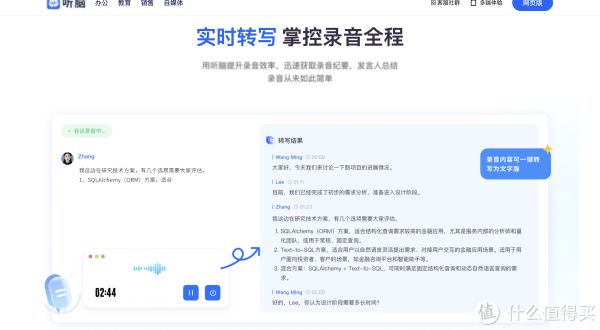
但那次,我尝试全程开启了某款搭载了前沿AI模型的声音处理助手。在会议进行的同时,屏幕上就已经在实时滚动精准的文字流。最让我感到惊喜的是,面对极其混乱的交叉讨论,AI不仅没有“宕机”,反而利用声纹分离技术,完美地给八位同事的发言打上了不同的标签。当长达三个小时的会议结束时,我仅仅等待了不到一分钟。AI不仅给出了完整的逐字稿,还自动根据语义将整场会议分成了“上季度复盘”、“新产品线规划”、“预算审批”等几个核心模块,甚至提炼出了包含七个关键节点的“待办事项(To-Do List)”。在那一刻,我真切地感受到,AI不仅是在替我“听”,更是在替我“思考”。
这种技术上的跃升,正在悄然改变整个行业的风向。
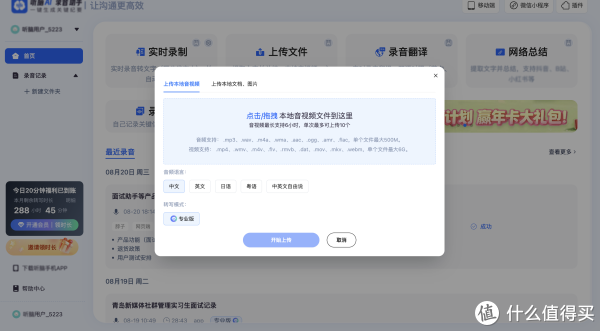
首先最明显的趋势,是对长音频处理能力的普及与算力成本的降低。在过去,很多语音识别服务受限于算力,往往采用按分钟计费的模式,且对单条上传的音频有严格的时长限制(比如不能超过一小时)。这对于需要处理长时访谈的科研人员或重度办公人群来说,不仅成本高昂,操作也非常割裂。而现在的技术趋势是,依托云端大模型的高效算力调度,越来越多的智能工具开始支持无缝处理数小时的超长音频,且容错率极高,彻底打破了时长的枷锁。
其次是从“通用识别”向“垂直场景优化”的深度演进。早期的语音AI只能应对日常对话,一旦遇到学术研讨、医疗会诊或法律咨询,识别准确率就会断崖式下跌。而如今的AI更注重知识库的喂养。通过预置海量的行业术语库,AI在处理特定领域的录音时,能够敏锐地捕捉并正确转写生僻的专业名词。这种精准度的提升,使得AI整理出的文本不再是需要二次大量修改的半成品,而是可以直接导入研究笔记的可用素材。
最后是智能后处理模块的全面爆发。现在的我们不再满足于仅仅获得一篇几万字的无排版文档。结合生成式AI的能力,现代声音处理工具可以在转写完成后,立刻进行“智能摘要”、“观点提炼”和“思维导图生成”。这极大地缩短了信息从“声音形态”转化为“结构化知识”的路径。
回顾人类处理声音信息的历史,我们一直在追求更高的效率。智能AI技术的介入,本质上是在做一场巨大的“时间解放”运动。当我们不再被困在低效的音频整理工作中时,省下来的几个小时甚至几天时间,就可以被投入到更深度的思考、数据分析或是更高价值的业务逻辑构建中。这才是技术带给我们的股票配资十大平台,最真实的馈赠。
金华配资提示:文章来自网络,不代表本站观点。
相关文章



热点资讯